C Character Set
Learn via video course

Overview
Character Set includes a set of valid characters we can use in our program in different environments. C language has broadly two character sets.
- Source Character Set (SCS): SCS is used to parse the source code into internal representation before preprocessing phase. This set includes Basic Character Set and White-space Characters.
- Execution Character Set (ECS): ECS is used to store character string constants. Other than Basic Character Set, this set contains Control Characters and Escape Sequences.
Scope of the Article
- This article discusses the history of character encoding. Here, we talk about an old form of encoding called EBCDIC, ASCII, and the current standard Unicode.
- Further, different types of Character Sets in C are explained with the usage of utility functions present in C.
Backstory
Character is 1-byte information that denotes alphabets, digits, and some special characters like !, @, etc. So simple it seems, but it has a long history of varying standards like EBCDIC, ASCII, etc. Read on...
In the early days, there used to be an encoding system called Extended Binary-Coded Decimal Interchange Code(EBCDIC), developed by IBM. EBCDIC can support 256 different types of characters. A few important features of EBCDIC are:
- Each character fits in 8 bits.
- The same type of characters are not grouped together.
- Different versions of EBCDIC are not compatible.
Slowly, ASCII encoding was developed in 1963 by American Standards Association (ASA). ASCII was simpler and accommodated fewer characters than EBCDIC. It has 128 characters and needs 7 bits to display a single character.
Another Conflict
Most computers were using 8-bit bytes and ASCII requires only 7 bits (i.e., 27 = 128 characters), We have one extra bit to spare. Soon, few organizations developed their own conventions for [128, 255] characters. IBM developed the OEM character set, which included peculiar characters like |, Ã, Æ etc. IBM changed these character sets, i.e., [128, 255] according to every country. For example, character code 130 displays é in Europe, and it shows ℷ in Israel. If this appears as a small issue, wait until Asian languages come into the picture with thousands of characters! In these difficult times, slowly a standard was making its way...
Unicode Era
Unlike directly converting character code into binary, Unicode has a different perspective on characters. This allows Unicode to accommodate an unlimited number of characters (in different types of encodings). This article doesn't discuss the implementations of Unicode, but here are the key points to note:
- Unicode is just a standard. UTF-8, UTF-16 etc... are actual encodings.
- Popular Myth: UTF-8 requires 2 bytes (16 bit) to store a character, Thus at max 216 (65,536) characters can be represented. This is false. Some characters are stored in 1 byte. Some are stored in 2 bytes. Some even require 6 bytes!
- Representing characters is not as simple as converting it into binary. Read more about UTF-8 encoding here
- UTF-8 is a superset of ASCII, i.e., characters with ASCII code [0, 127] can be represented with the same character code.
Introduction of C Character Set
Majorly, there are two character sets in C language.
-
Source Character Set: This is the set of characters that can be used to write source code. Before preprocessing phase, the first step of C PreProcessor (CPP) is to convert the source code's encoding into Source Character Set (SCS). Eg: A, Tab, B, SPACE, \n, etc.
-
Execution Character Set: This is the set of characters that can be interpreted by the running program. After preprocessing phase, CPP converts character and string constant's encoding into Execution Character Set (ECS). Eg: A, B, \a, etc.
 (https://drive.google.com/file/d/1XUuwf0KYQKbzECLIbswTGaCQWqpagIJ1/view?usp=sharing)
(https://drive.google.com/file/d/1XUuwf0KYQKbzECLIbswTGaCQWqpagIJ1/view?usp=sharing)
By default, CPP uses UTF-8 encoding for both Source and Execution Character Sets. User can change them with below compiler flags.
- -finput-charset is used to set SCS.
- Usage: gcc main.c -finput-charset=UTF-8
- -fexec-charset is used to set ECS.
- Usage: gcc main.c -fexec-charset=UTF-8
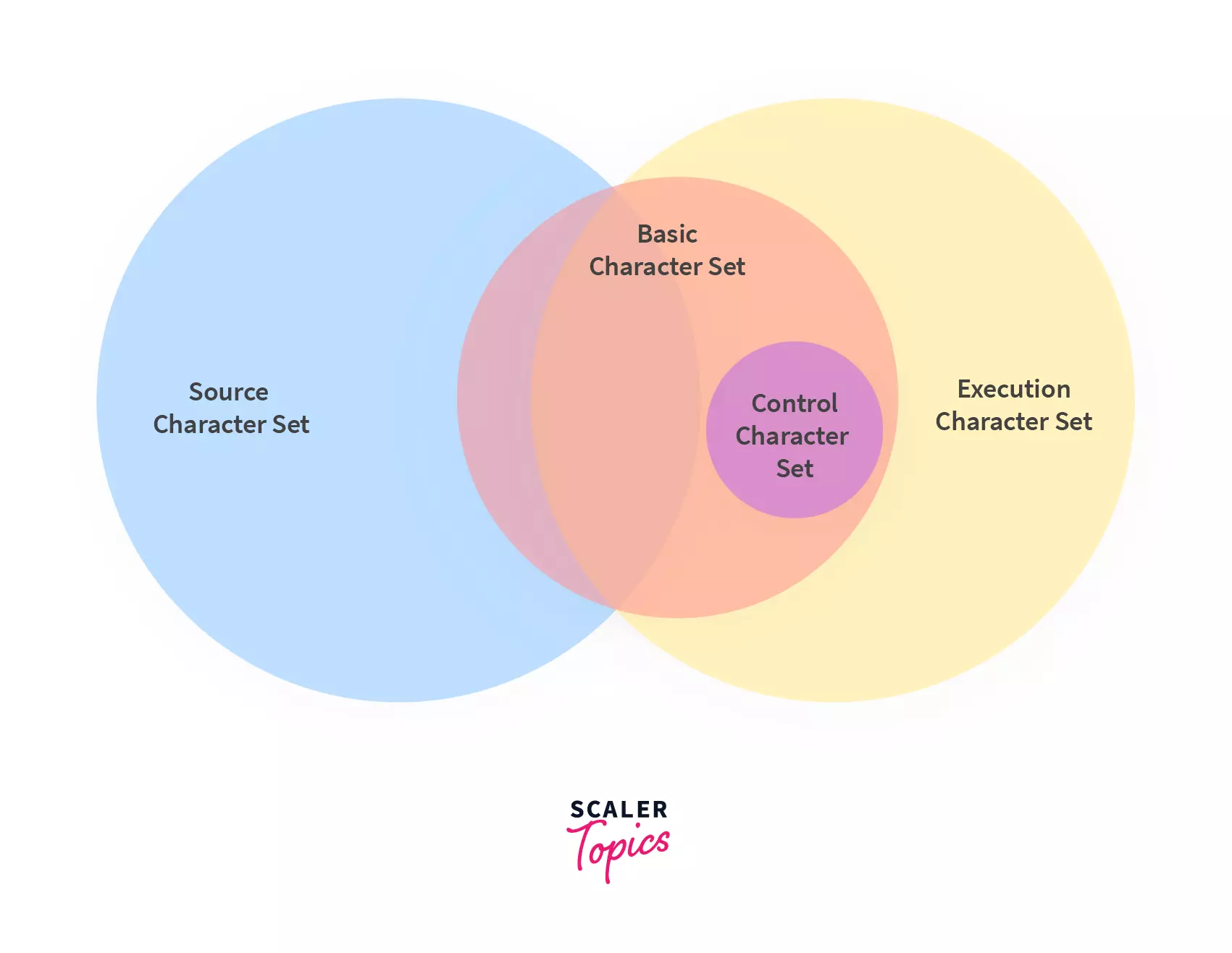
Note: Basic Character Set is common between SCS and ECS
Basic Character Set
Source and Execution Character sets have few common characters. The set of common characters is called Basic Character Set. Let's discuss more about it below:
-
Alphabets: which includes both uppercase and lowercase characters. ASCII code of uppercase characters is in the range [65, 90] whereas ASCII code of lowercase characters is in the range [97, 122]. Eg: A, B, a, b etc.
- Uppercase and lowercase characters differ by just one bit.
- Utility Functions: isalpha, islower, isupper check whether the character is alphabet, lowercase alphabet, uppercase alphabet respectively. tolower, toupper transforms the alphabets to appropriate case.
-
Digits: Includes digits from 0 to 9 (inclusive). ASCII code of digits is in the range [48, 57]. Eg: 0, 1, 2 etc.
- Utility functions: isdigit checks whether the input character is a digit. isalnum checks whether a character is alphanumeric character.
-
Punctuation/Special Characters: The default C locale classifies the below characters as punctuation characters.
- Utility functions: ispunct checks whether a character is punctuation character. Below table contains the list of all punctuation characters, ASCII code and their usecases.
Character ASCII Detail ! 33 Exclamation mark, exclamation point, or bang. " 34 Quote, quotation mark, or inverted commas. # 35 Octothorpe, number, pound, sharp, or hash. $ 36 Dollar sign or generic currency. % 37 Percent. & 38 Ampersand, epershand, or and symbol. ' 39 Apostrophe or single quote. ( 40 Open or left parenthesis. ) 41 Close or right parenthesis. * 42 Asterisk, mathematical multiplication symbol, and sometimes referred to as a star. + 43 Plus. , 44 Comma. - 45 Hyphen, minus, or dash. . 46 Period, dot, or full stop. / 47 Forward slash, solidus, virgule, whack, and mathematical division symbol. : 58 Colon. ; 59 Semicolon. < 60 Less than or angle brackets. = 61 Equal. > 62 Greater than or angle brackets. ? 63 Question mark. @ 64 Ampersat, arobase, asperand, at, or at symbol. [ 91 Open bracket. \ 92 Backslash or reverse solidus. ] 93 Closed bracket. ^ 94 Caret or circumflex. _ 95 Underscore. ' 96 Acute, backquote, backtick, grave, grave accent, left quote, open quote, or a push. { 123 Open brace, squiggly brackets, or curly bracket. } 125 Close brace, squiggly brackets, or curly bracket. ~ 126 Tilde.
Control Character Set
These characters range from ASCII code 0 to 31 (inclusive) and 127th character. They are visually absent, but they do affect the program in different ways. For example: \a (BEL) character may cause a beep sound or screen flashing when printed, \b (BS) character moves the cursor one step back (Unlike Backspace on the keyboard, which erases the previous character).
- Utility Functions: iscntrl checks whether a character is a control character.
| ASCII | Abbreviation |
|---|---|
| 00 | NUL '\0' (null character) |
| 01 | SOH (start of heading) |
| 02 | STX (start of text) |
| 03 | ETX (end of text) |
| 04 | EOT (end of transmission) |
| 05 | ENQ (enquiry) |
| 06 | ACK (acknowledge) |
| 07 | BEL '\a' (bell) |
| 08 | BS '\b' (backspace) |
| 14 | SO (shift out) |
| 15 | SI (shift in) |
| 16 | DLE (data link escape) |
| 17 | DC1 (device control 1) |
| 18 | DC2 (device control 2) |
| 19 | DC3 (device control 3) |
| 20 | DC4 (device control 4) |
| 21 | NAK (negative ack.) |
| 22 | SYN (synchronous idle) |
| 23 | ETB (end of trans. blk) |
| 24 | CAN (cancel) |
| 25 | EM (end of medium) |
| 26 | SUB (substitute) |
| 27 | ESC (escape) |
| 28 | FS (file separator) |
| 29 | GS (group separator) |
| 30 | RS (record separator) |
| 31 | US (unit separator) |
| 127 | DEL (delete) |
-
Escape Sequences: These characters are a part of the Execution Character Set. These characters need a backslash(\) to identify them. It composes of 2 or more characters, but C PreProcessor treats them as a single character. Eg:\a, \b, \t etc...
-
White-space characters: These characters are a part of the Source Character Set. They affect the text on display, but are visually blank.
-
Utility Functions: isspace checks whether a character is white-space character.
Character ASCII Detail <space> 32 space (SPC) \t 9 horizontal tab (TAB) \n 10 newline (LF) \v 11 vertical tab (VT) \f 12 feed (FF) \r 13 carriage return (CR)
Printing all characters
Output
- ctype.h contains utility functions isalpha, isdigit. So, we included it at the top.
- Since Control characters are visually absent, we're not printing them, i.e., we started the loop at ASCII code 32.
- With the help of utility functions we're finding the type of the character.
- The output of this program is a formatted markdown table of characters.
Summary
- C language has two types of character sets namely: Source Character Set (SCS), Execution Character Set (ECS).
- C Source code is converted into SCS by CPP before preprocessing. CPP converts character and string constants into ECS after preprocessing.
- Space characters are visually blank but they affect the text. Control characters are visually absent, but they have different functions to perform such as causing a bell sound (\a), moving the cursor to the left (\b) etc.
- ctype.h has a lot of utility functions to work with characters like isalpha, isdigit etc.