Difference Between Compiler and Interpreter
Learn via video course

Overview
Compilers and Interpreters are programs that translate a source code (a file that contains the program) to a machine code that can be understood by a processor. A compiler translates source code as a whole and performs various optimization techniques before mapping it to executable machine code. But, an interpreter translates source code as needed in runtime – it maps source code to machine code almost immediately.
Scope
-
This article discusses the introduction of compilers and interpreters. It will cover the mechanism like how these all things operate, the design space, and different ways to construct interpreters and compilers.
-
The article presents the difference between compiler and interpreter along with key points on their advantages and disadvantages and also the internal concepts to understand the working of compiler and interpreter.
Introduction
Programming languages are designed to express the computational solutions to the domain-specific problems that could be a simple mathematics computation or maybe a complex algorithmic challenge, but overall the goal is to have a human-readable language. On the other hand, the computer executes instructions in its native language – a sequence of binaries that encodes an operation. The world of computers and humans is linked together by a program that translates the language X to Y.
Compilers and interpreters have the task of representing the meaning of a program and translating it into a representation that your computer can execute. Suffice to say that code is text data that gets translated into a machine language. Depending on the implementation, the translation process may vary.
The compiler creates a meaningful representation of the program and then turns it into a set of instructions that a specific processor can perform. But, interpreters translate the source code whenever necessary and execute it almost immediately. In the further article, we will explore the detailed difference between compiler and interpreter.
What is a Compiler?
A compiler is a program that forms a representation of the meaning of the code and generates a set of instructions that computers can execute. A compiler translates the source code as a whole. Compiler-generated programs tend to perform faster than interpreted programs. Compilers demand the necessary information to enable advanced optimization and render efficient code representation. The optimization process can get the values in an expression during compilation.
The compilation is a sequence of transformations that translates source language to a target language. A target language may be in the form of another programming language as some compilers like Dart can translate to JavaScript. Meanwhile, other compilers like Java produce a bytecode which gets interpreted by the JVM(Java Virtual Machine) to produce a set of instructions that processors can execute.
That said, it is worth mentioning that compilers may be implemented for different design purposes. The compiler designs and some examples of programming languages that implement them are enumerated below:
| Type | Design goals | Examples |
|---|---|---|
| Cross-compiler | generates executable code for another platform | Microsoft C, MinGW |
| Transpiler | translates source codes between high-level languages | Cfront, ScriptSharp |
| Decompiler | translates low-level language to high-level language | Disassembler |
| Compiler-Compiler | generates a parser, interpreter, or compiler from some form of formal description of grammar-based language. | ANTLR, Bison |
Phases of Compilation
Compiler design usually follows a simple architecture that is composed of Front-end, Middle-end, and Back-end. Note that this section serves as a tour of compiler development, we do not aim to get a comprehensive hold on each phase mentioned.
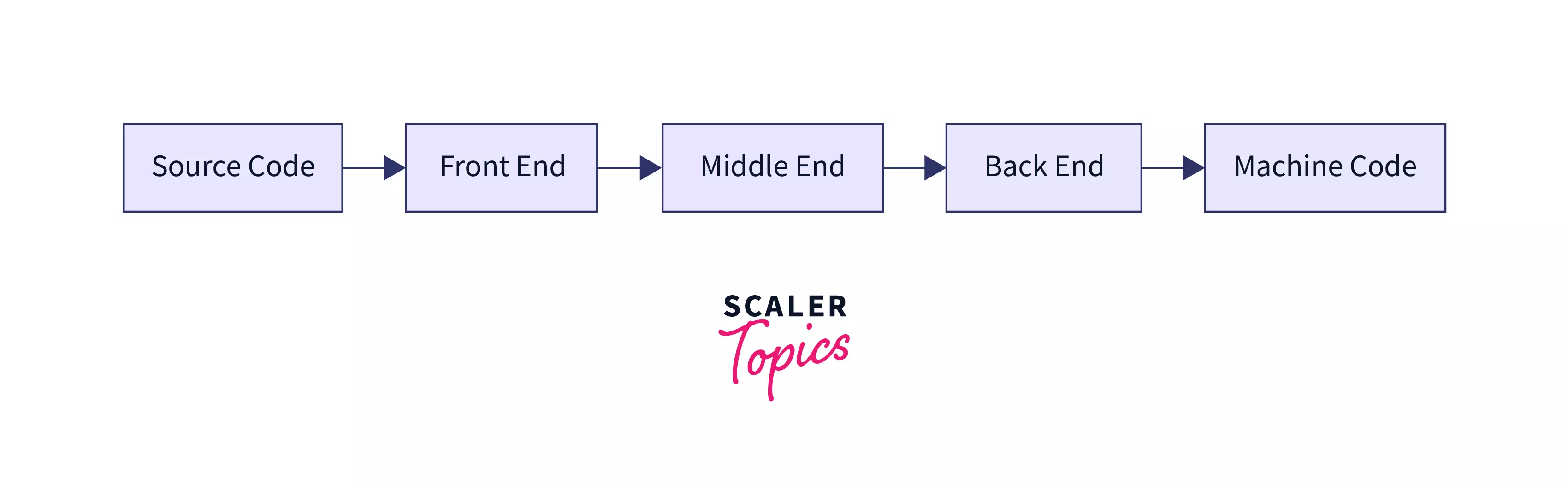
The front-end component scans and verifies the grammar (syntax) and the meaning (semantics) expressed in the program. The front-end handles identifying each token from the text file (source code), validating syntactical soundness, performing semantic analysis, and generating an abstract representation of the source code in the form of an Abstract Syntax Tree.
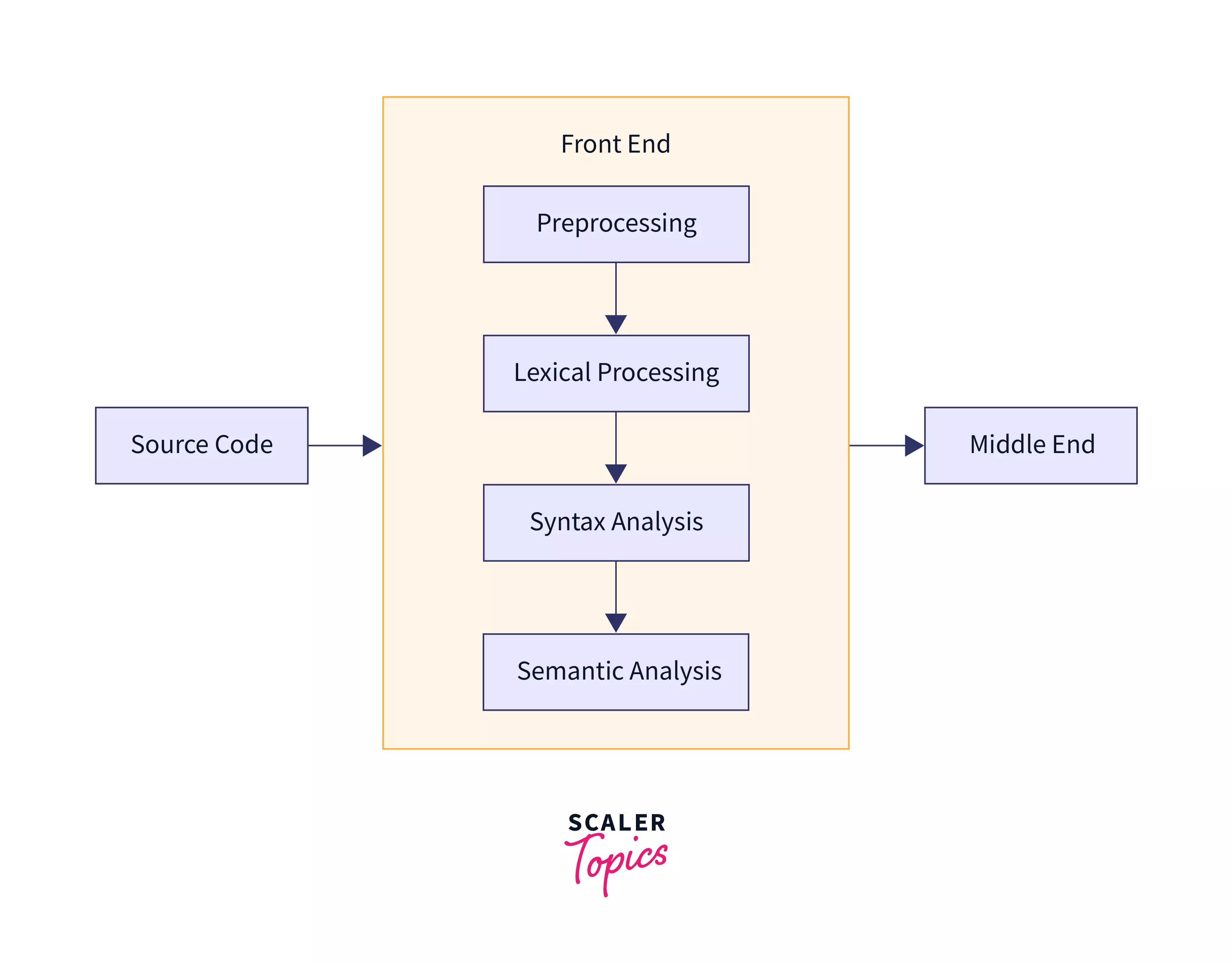
Front-end components include the following series of transformations and analysis:
-
Preprocessing. The lines of code which start with # character are being preprocessed in this phase,these steps of compilation involve the substitution of macros(a segment of code) to valid syntactical forms, file inclusion because when we import the library, it doesn't contain the actual code, i.e. #include<stdio.h> and the conditional compiled directives(a technique to execute or not execute a particular statement of code based on some condition). This results in a normalized form of the program that doesn't contain any preprocessing directives.
-
Lexical analysis. This process breaks down the source code into a sequence of lexical tokens. In other words, lexical analysis is the process of identifying certain categories of grammar in the same way that you identify the parts of speech in this sentence. As such, it contains two minor operations: scanning and evaluating.
-
Scanning is the process of breaking down the text into tokens and categorizing tokens based on the class of syntactic units i.e., the token can be of type- constant, identifier, operator, special character, keywords etc.
-
Evaluating involves the conversion of lexemes(a sequence of characters that matches a pattern) into processed values, e.g., 5+3 -> 8.
-
-
Syntax analysis. Syntax analysis examines the token sequence and identifies the syntactic structure of the program. By the end of this phase, a syntax tree (also called parse tree) is generated.

- Semantic Analysis. This phase has the task of annotating semantic information to the syntax tree, which results in the creation of a symbol table. A symbol table contains the parsed units with relation to information regarding their appearance in the source. Let's take a closer example:
| Symbol Name | Type | Scope |
|---|---|---|
| sum_of_square | function, double | local |
| a | double | function parameter |
| b | double | function parameter |
Looking at a naïve example of a symbol table, it contains type information and the scope of objects. Semantic analysis may involve type checking, definite assignment, or object binding, which forms the basis for checking whether your code is meaningful. For instance, what does it mean to add a string with an integer? JavaScript allows this meaningless statement to happen, which leads to more bugs.
Some compilers prove invariance(a property of mathematical object which states the object will remain unchanged after some operations or transformation of certain type) and other properties which results in a robust and reliable system.

The middle-end optimizes the generated parse tree – which is expressed in an intermediate representation (IR). Most of the tasks in the middle-end layer are provided by most compiler frameworks such as LLVM. This phase may include the following:
-
Analysis - This process gathers program information from the parse tree and checks certain cases where optimization may take place.
-
Optimization - Transforms IR to its faster equivalent form.
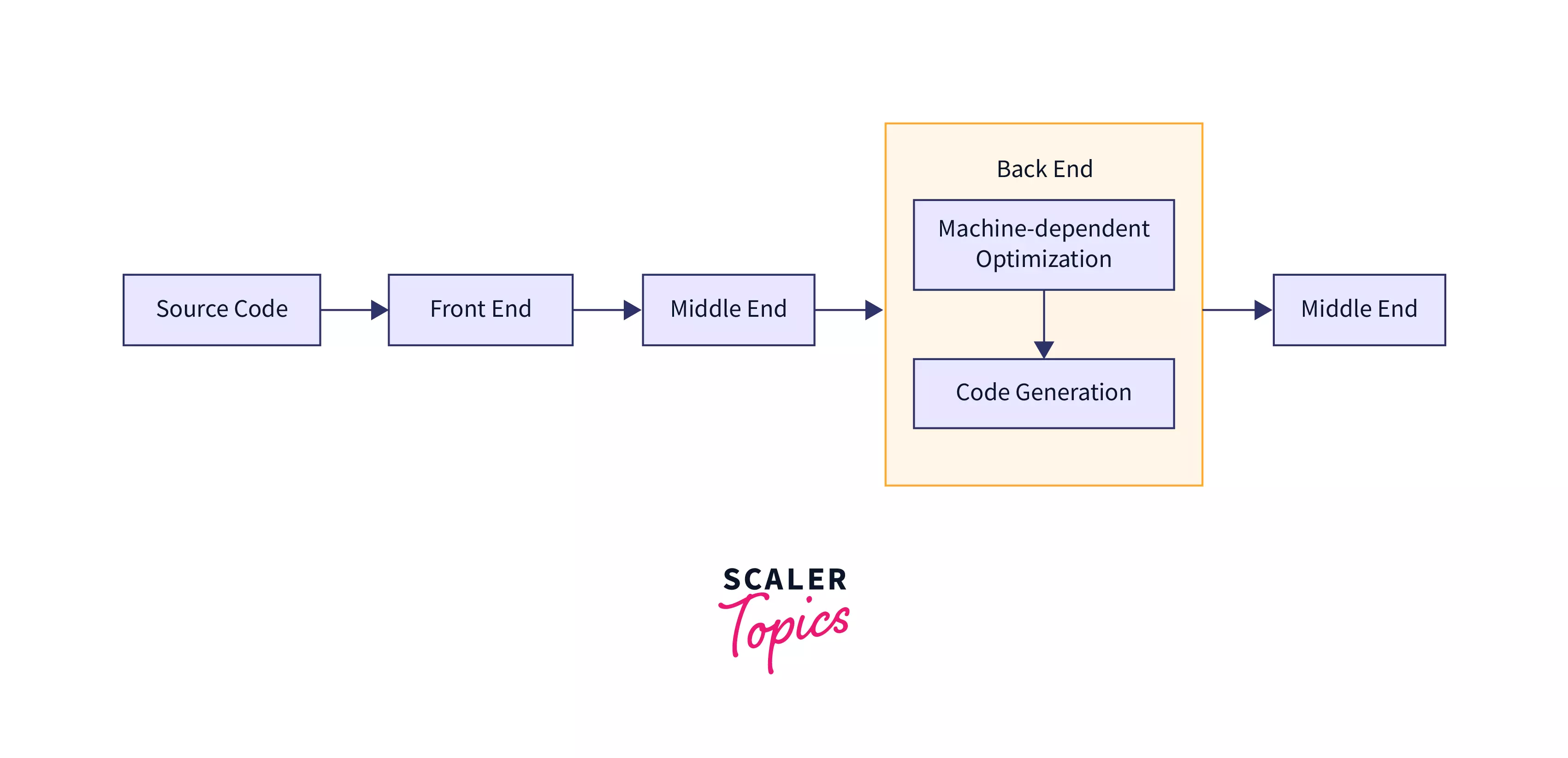
The back-end component of a compiler handles the mapping of optimized IR to CPU architecture-specific optimizations and code generation, which include the following:
- Machine dependent optimizations - this pertains to the set of optimization a CPU architecture permits.
- Code generation - this translates the assembly instruction generated after machine-dependent optimization into the native machine language of the target system.
Digression:
C and Java are interesting candidates of compiled languages that both produce an executable upon compilation. A C program compiles down to assembly code which, when executed, prompts to assemble relocatable object code. On the other hand, Java compiles to a byte code which is an intermediate representation of assembly-like instructions that are interpreted by the JVM upon execution.
In the case of Java, we observed how one may use an interpreter for mapping low-level byte code to assembly instructions that are relative to the target machine this way, it gives Java portability and performance. A dedicated section below discuss interpreters more thoroughly.
What is an Interpreter?
An interpreter generates machine code by translating each line of code one by one. Because the interpreter translates your program at runtime, it has fewer opportunities for performing optimization. Meanwhile, translating programs at runtime results in a dynamic type system that offers flexibility and ease of handling errors – because compiled languages are notorious for their cryptic error messages.
In a compiled language, the re-compilation process may require restarting the entire compilation even when very tiny pieces of the code are being changed. This process could take as long as 30 - 40 mins for large projects in some compilers. As a side note, modern compilers have optimized for this (e.g. Dart VM Hot Reload to minimize development time and maximize productivity but a defining feature of interpreted programming languages is meant for fast prototyping and agile development.
Interpreters come with different design goals. Let us take a look at some interpreters and list down their purpose:
| Type | Design goals | Examples |
|---|---|---|
| Bytecode interpreter | translates a bytecode and maps it to a machine language | CLISP, .NET |
| Threaded code interpreter | maps pointers gathered from a high-level language to specific machine instruction | N/A |
| Just-In-Time (JIT) compilation | intermediate representation of the language is compiled to native machine code during runtime | Julia, PyPy |
Note that JIT is a hybrid form of a compiler-interpreter architecture.
Phases of Interpretation
As we discussed in the previous section, the design space of interpreters may range depending on its goal – from translating high-level language directly to native code to translating compiler-optimized object code to machine code. As a result, performance may depend on its implementation and design.
Since we already discussed the more elaborate model of translation (compilation), interpretation is a simpler model that removes considerable sections of compilation.
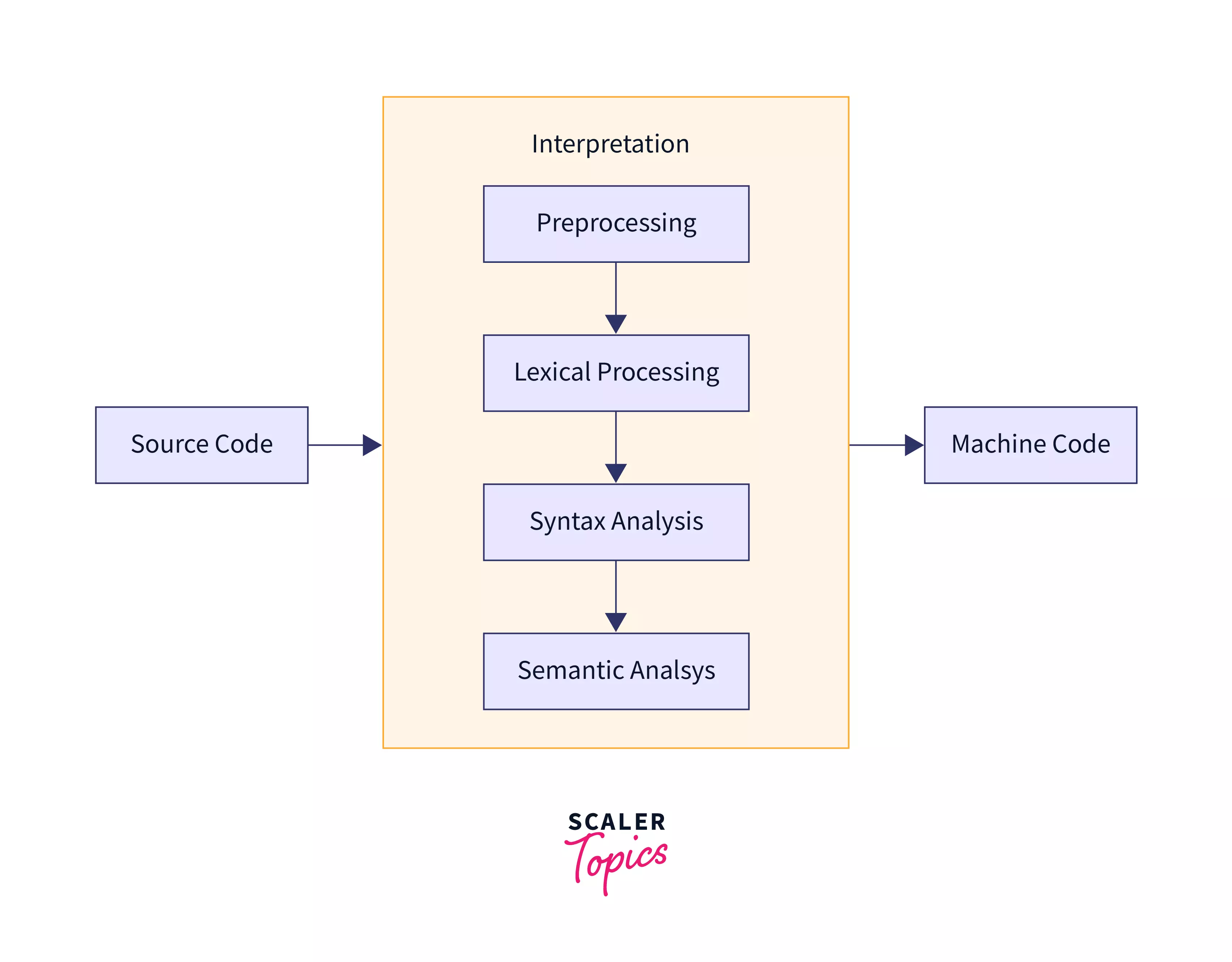
- Preprocessing: It involves annotating lines of code, and substituting macros for normalizing code representation.
- Lexical analysis: It involves substituting tokens and mapping them to a category of grammar they belong e.g. finding a set of all variables in the program.
- Syntax analysis: It involves checking for invalid syntax expressed in the program.
- Semantic analysis: It involves checking for meaningful operations and eliminates the possible instances of meaningless expressions e.g. string + int, some interpreters might call for type promotions which strongly typed languages will call for runtime error (try this in JavaScript and Python.
- Machine Code generation: The code generation may involve a compilation process or direct mapping to machine instructions. This depends on the intended design of a programming language.
Digression: The case of Python and Julia
Both Python and Julia are interesting candidates to talk about interpreters. The default implementation of Python is called CPython which involves a compilation process for mapping source code to native C-bindings. Since Python is a dynamic language, its compiler cannot assume anything about type information hence everything is represented with a universal type called a Python Object, this results in fewer opportunities for optimization.
In contrast, Julia’s JIT compiler optimizes its generated machine code as one can specify type information (among other things) in the language. If we compare Python with Julia we can notice the significant difference on average and start-up execution of the code. Calling up a JIT compiler would require more time to execute at first since the code has to be compiled and optimized for generating efficient machine code, which incurs an overhead. Meanwhile, Python translates code immediately with minimal compilation time. On average, however, it is expected that JIT-ed code outperforms Interpreted code.
How does a Compiler and an Interpreter Work?
Here we will see the difference between compiler and interpreter along with the flowchart to illustrate the difference in workflow of compiler vs interpreter.
Compilation

Interpretation

Difference between Compiler and Interpreter
| Compiler | Interpreter |
|---|---|
| Types are determined during compilation. | Types are determined during runtime. |
| Translation of the program happens during compilation. | Translation of the program happens during runtime, i.e. code are interpreted line by line. |
| Generated machine code is stored in a secondary disk as executable. | Since the execution happens immediately after the program has been translated, the machine code is temporarily stored in RAM. |
| Since compilers can perform compile-time optimizations, it performs significantly faster than interpreted language. | Since interpreters translate the code during runtime, there is very little room for optimization as the translation process incurs performance penalties which result in slower performance. |
| Compiled languages are best-suited for performance critical applications such as utility programs for an operating system. | Interpreted languages are best suited for task automation and scripting. |
Role of a Compiler
We know that a compiler evaluates source code as a whole, this translation model maintains certain properties so we are able to assume certain forms of knowledge about the program. Because of this, we can perform techniques that check whether a given expression has meaning. As a result, we can meet not only performant but also secure software applications.
As we observed, the stages of compilation have more layers dedicated to programming analysis and optimization. The implementation of a compiler often result to the following properties of a programming language:
- Static Type System
- Efficient Executable code
Some advanced techniques can be done almost exclusively with a compiler such as:
- Code optimization
- Type checking
- Profiling for program correctness
- Verifying program invariance
Role of an Interpreter
- The interest in Interpreter development came from overcoming the limitations of computer memory in 1952 (Bennett, Prinz & Woods, 1952).
- Most interpreters are designed for on-the-fly code execution that runs the code on demand.
- Interpreted programming languages mostly take their translation time in the interpreter resulting in a dynamic execution of a program.
- Generated expressions on demand come naturally with interpreted languages.
High-level Languages
High-level languages are programming languages with considerable layers of abstraction from Assembly. For example, languages like Python and JavaScript are high-level as it hides the underlying details like memory model and machine architecture.
Programming languages are developed to find the balance between development time and performance. Because let’s face it, even if C and C++ give you the tools to develop a high-performance codebase, it could take weeks to write one.
Machine Languages
Machine languages pertain to the raw form of data that a computer executes. Assembly language is a human-oriented form of machine language that contains a set of instructions a computer can execute. Each instruction specified in the assembly language reflects the set of tasks to be executed by the CPU and other computer resources. That said, machine languages tend to reflect the memory model and architecture-specific instructions of the computer.
Object Code
An object code is the result of the compilation process. Since different processors have different architectural layouts e.g. AMD, Intel, ARM, Qualcomm, and others, compiled binaries have to be portable. To attain this, the compiler generates an object code that represents an intermediary code which is converted to machine code at runtime.
Advantages and Disadvantages of Interpreter and Compiler
The discussion of compiler vs interpreter is here extended to illustrate the advantages and disadvantages of both of them.
Compilers
-
Advantages
- Compilers convert source code to an optimized set of computer instructions that are highly performant.
- Compilers can check for invariance and confirm the program's ideal properties to account for resource safety.
-
Disadvantages
- Often difficult to develop, compiler errors and warnings can be difficult to understand
- Because it expects some properties to be met upon compilation, you are responsible to live up to that promise. For instance, const entities are expected to remain constant, violating this precondition may result in a painstaking process of arguing with the compiler.
- As compilation takes time to produce efficient executables, the development time can take longer.
Interpreters
- Advantages
- Lazy evaluation are often implemented for most interpreted programming languages such as Perl, Haskell, Scheme, and Python. Lazy evaluation allows you to compute an infinitely long data structure without worrying about memory. (This is not unique to Interpreted languages, but most interpreted languages support this feature)
- Interpreters tend to have a dynamic type system which makes them easier to write and reason with.
- Since a dynamic type system means more flexible types, generic programming is simpler to implement as you worry less about Runtime Type Information.
- Interpreted languages tend to create a more productive developer experience because it does not incur developer time to compile and it executes the code immediately.
- Disadvantages
- Not as performant as compiled executables (although JIT compilers overcome this problem)
Conclusion
-
High-level programming language development is a result of wanting to strike a balance between performance and productivity. A computer can only understand binaries but implement problems. Expressing solutions in a machine language are difficult to keep track of, so a human-oriented form of language is represented as our way of communicating with the computer.
-
The task that compilers and interpreters have in common is that of translation. The straightforward difference between compiler and interpreter is, a compiler translates source code as a whole to machine code, but the interpreter does the same for one line at a time.
-
Programming language implementation may use both compilers and interpreters to suit their problem domain – as languages are developed to solve a particular set of problems that exist in a domain.
-
Compilers generate high-performance machine code as it may alter the sequence of the program and transform its expressions into a highly optimized machine code.
-
Interpreters are great for dynamic systems. Most interpreted languages give you greater developer experience in terms of productivity.